快科技8月23日消息,摩尔线程官方宣布,音频理解大模型”MooER”(摩耳)已经正式开源,并公布在GitHub上:https://github.com/MooreThreads/MooER
目前开源的内容包括推理代码,以及5000小时数据训练的模型,后续还将开源训练代码,以及基于8万小时数据训练的模型。
摩尔线程希望,能够在语音大模型的方法演进和技术落地方面为社区做出贡献。
MooER是业界首个基于国产全功能GPU进行训练和推理的大型开源语音模型,依托摩尔线程的夸娥(KUAE)智算平台,并得益于自研的创新算法和高效计算资源的结合,仅用38个小时,就完成了5000小时音频数据和伪标签的训练。
MooER不仅支持中文和英文的语音识别,还具备中译英的语音翻译能力,并在多个语音识别领域的测试集中,展现出了领先或至少持平的优异表现。
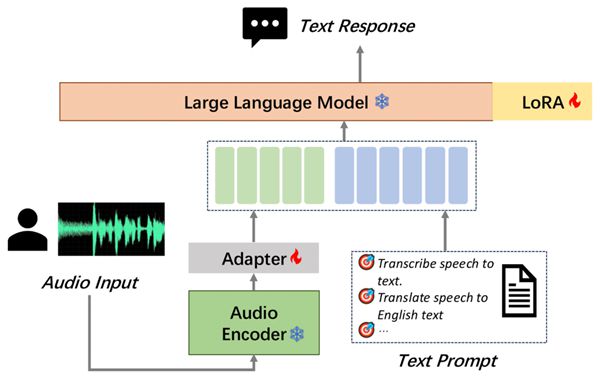
MooER的模型结构包括Encoder、Adapter、Decoder(LLM)三个部分。
其中,Encoder对输入的原始音频进行建模,提取特征并获取表征向量。
Encoder的输出会送到Adapter进一步下采样,使得每120ms音频输出一组音频Embedding。
音频Embedding和文本的Prompt Embedding拼接后,再送进LLM进行对应的下游任务,如语音识别(ASR)、语音翻译(AST)等。
在模型训练阶段,融合了语音模态和文本模态的数据会按以下形式输入到LLM:

摩尔线程使用开源的Paraformer语音编码器、Qwen2-7B-instruct大语言模型,初始化Encoder和LLM模块,并随机初始化Adapter模块。
训练过程中,Encoder始终固定参数,Adapter和LLM会参与训练和梯度更新。
利用自研的夸娥智算平台,摩尔线程使用DeepSpeed框架和Zero2策略,基于BF16精度进行训练和推理。
经实验发现,训练过程中更新LLM参数能够提升最终音频理解任务的效果。
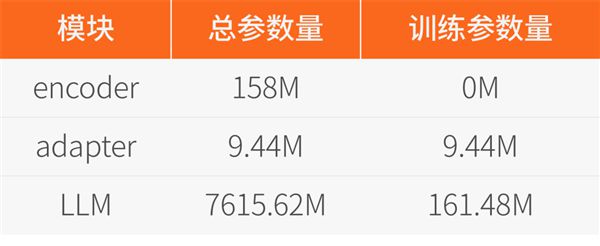
为了提升训练效率,摩尔线程采用了LoRA技术,仅更新2%的LLM参数。具体的模型参数规模如下:
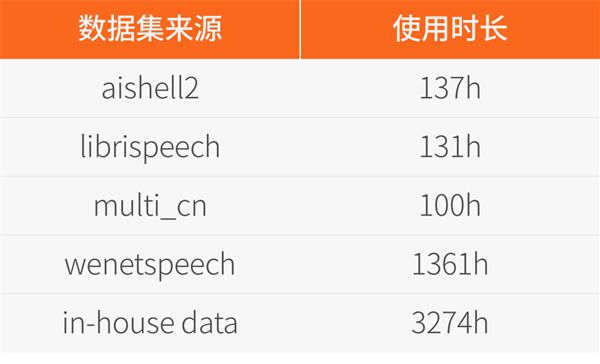
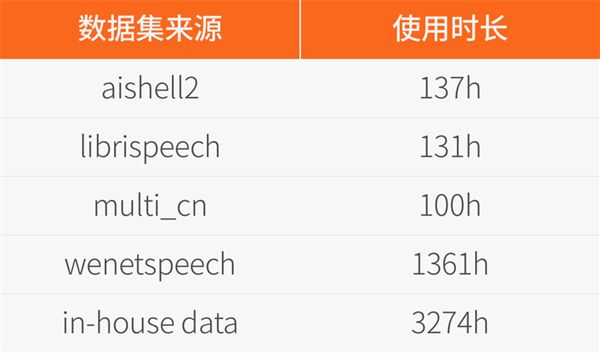
该模型的训练数据MT5K(MT 5000h)由部分开源数据和内部数据构成,内部数据的语音识别标签均是由第三方云服务得到的伪标签。
语音识别的伪标签经过一个文本翻译模型后,得到语音翻译的伪标签,且没有对这些伪标签数据做任何的人工筛选。
具体数据来源和对应的规模如下:
摩尔线程将MooER与多个开源的音频理解大模型进行了对比,包括Paraformer、SenseVoice、Qwen-audio、Whisper-large-v3、SeamlessM4T-v2等。这些模型的训练规模从几万小时到上百万小时不等。
对比结果显示,开源模型MooER-5K在六个中文测试集上的CER(字错误率)达到4.21%,在六个英文测试集的WER(词错误率)为17.98%,与其它开源模型相比,效果更优或几乎持平。
特别是在Covost2 zh2en中译英测试集上,MooER的BLEU分数达到了25.2,显著优于其他开源模型,取得了可与工业水平相媲美的效果。
基于内部8万小时数据训练的MooER-80k模型,在上述中文测试集上的CER达到了3.50%,在英文测试集上的WER到达了12.66%。
与此同时,摩尔线程还得到一些有趣的结论,可以为数据资源和计算资源有限的开发者提供一些建议:
▼Encoder的选择。
分别对比无监督(Self-Supervised Learning)训练的W2v-bert 2.0、半监督(Semi-Supervised Learning)训练的Whisper v3、有监督(Supervised Learning)训练的Paraformer。
采用无监督训练得到的Encoder必须参与到训练过程中,否则模型很难收敛。
综合考虑模型效果、参数量以及训练和推理的效率,选择Paraformer作为Encoder。
▼音频建模粒度很关键。
尝试使用240ms、180ms和120ms的粒度进行建模,并发现这一参数对音频与文本的融合效果具有重要影响,同时会影响模型的最终效果和训练的收敛速度。
经过评估,最终选择每120ms输出一个音频Embedding。
▼快速适应到目标垂类。
仅使用了140h~150h的英文数据进行训练,可以在6个不同来源的英文的测试集上取得一定效果。
同时尝试将任务迁移到语音翻译(AST)领域,取得了很好的效果。
相信这个方法同样也适用于小语种、方言或其它低资源的音频理解任务。
▼LLM对音频理解任务的影响。
在模型训练过程中采用LoRA技术对LLM参数进行更新,可以使训练更快收敛,并且最终取得更好的效果。
同时,音频理解任务上的效果也会随着基础LLM效果提升而提升。
更多技术细节,请参考技术文档:
https://arxiv.org/pdf/2408.05101



























